
Utilization map for when user needs data
(Note)For a comprehensive introduction to PatentPia data, please click on the [Link], but be sure to check out the Full data map, Data Core Features, and Data FAQ on this page first.
PatentPia data asset map
Representative data assets held by PatentPia include i) patent/non-patent data assets, ii) classification assets for keywords/companies, etc.
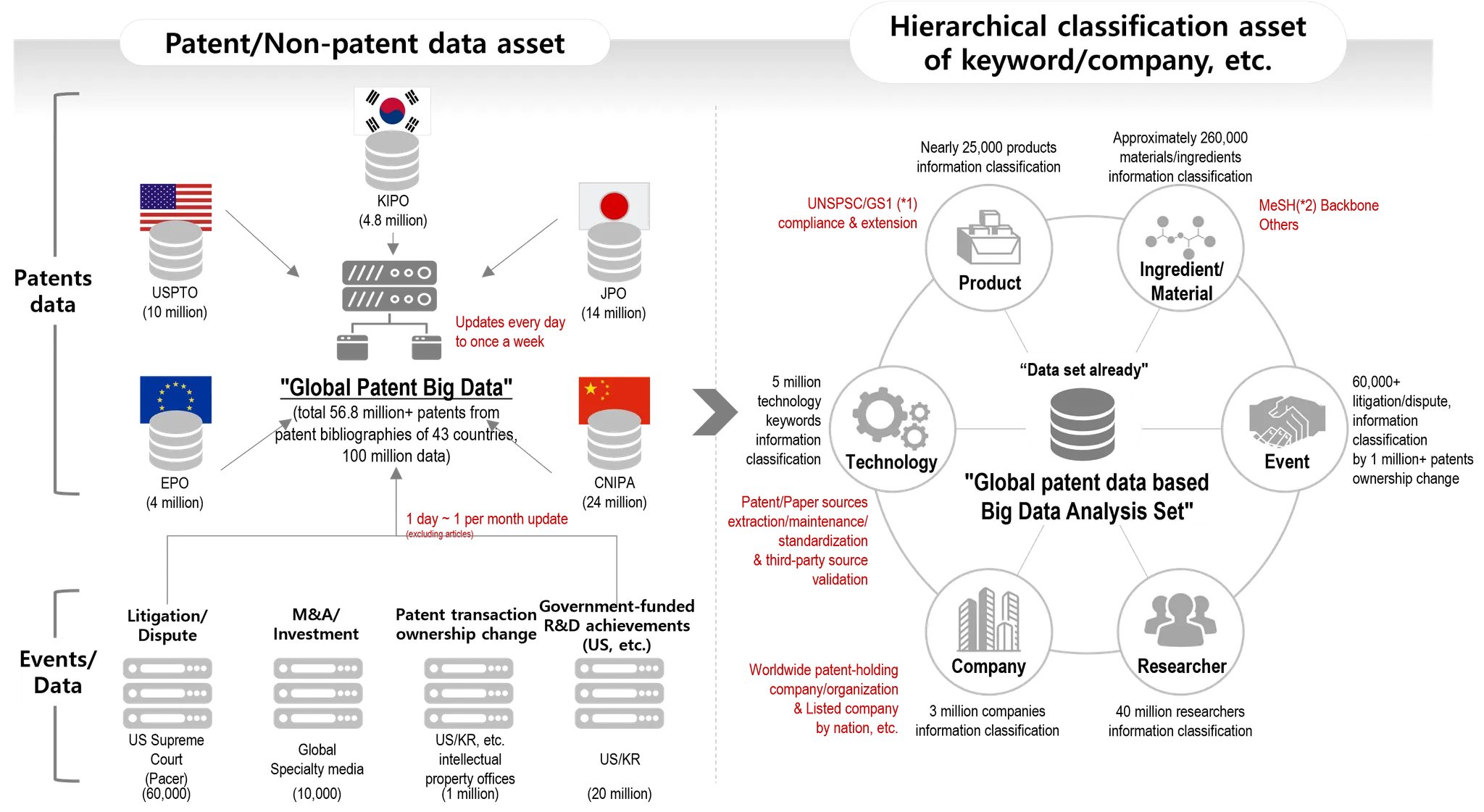
PatentPia data asset roadmap
PatentPia has data assets based on global patent data. Currently, we are building paper and web data assets, and eventually combine nation-specific industry and technology policy data with our existing data assets.
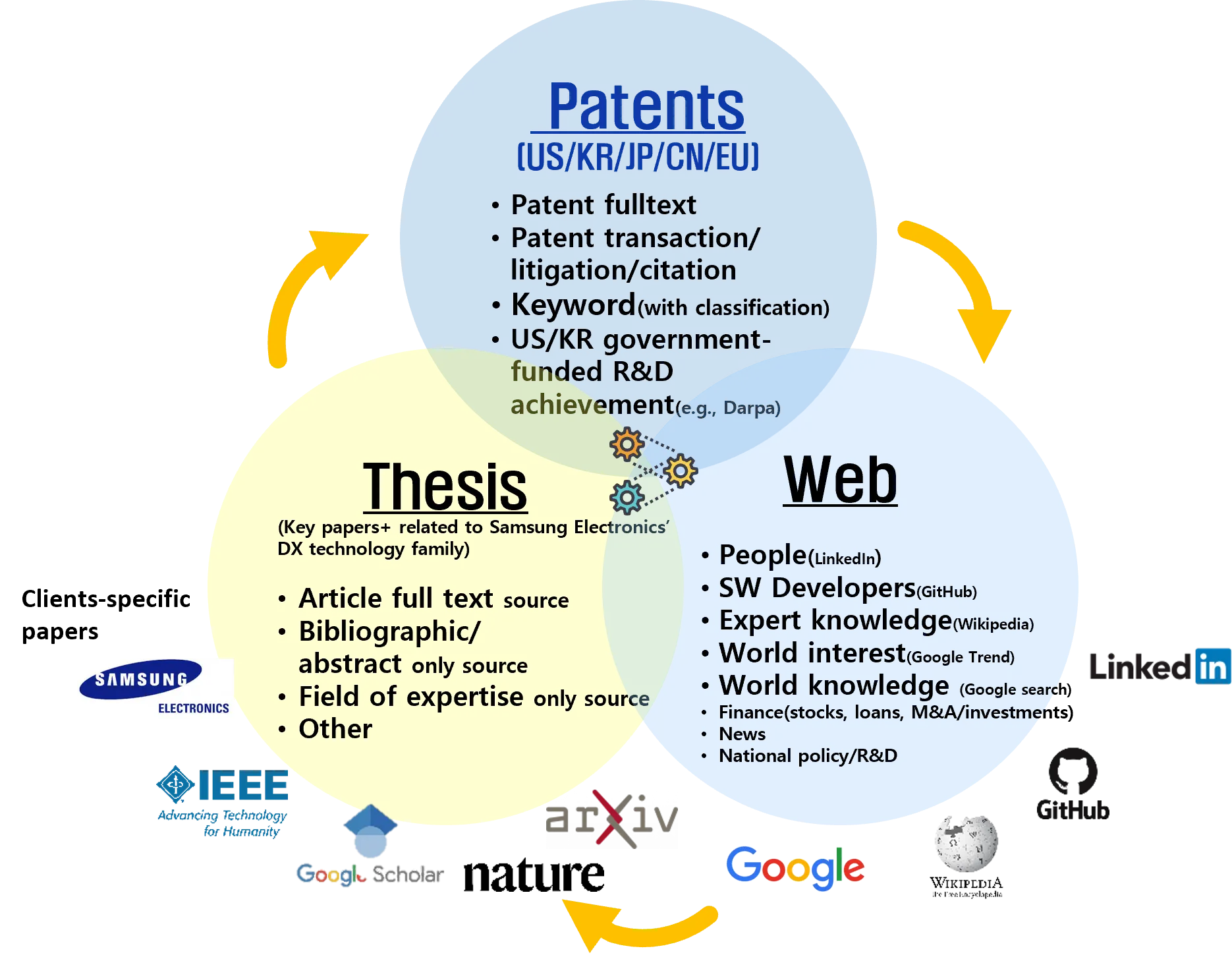
Introduction to patent data processing
Patent number data (with/without classification) → Data on nearly anything that can be generated from patent numbers
If the patent number has a classification mapped to it, the classification mapping information will also be combined in the final data.
There are two types of data: data with 1 correspondence per patent and data with n correspondences per patent: data with 1 correspondence per patent includes: i) date, ii) number, iii) whether or not, total/measure (per yearly), etc. data with n correspondences per patent includes: i) right holder, ii) inventor, iii) patent classification, iv) related patents in each nation, v) related events, vi) keywords, vii) representative, etc.
Patent-specific 1:1 correspondence bibliographic and aggregate data
The bibliographic data by patent includes not only 1:1 correspondence data, but also 1:N correspondence i) subject data such as right holders, inventors, agents, etc., and ii) nation data with patent families.
For right holders, the organization attributes of the right holder include i) whether it is a company, ii) whether it is researchers at universities/research institutes, and iii) whether it is an NPE. Additional data on the right holder is also included, such as the nationality of the right holder and whether or not the patent is located in a tax haven. Meanwhile, for transacted patents, the right holder is also provided, segmented into i) current right holder, ii) previous right holder, iii) applicant, etc.
Then, as aggregate data, there are yearly and overall i) Events data (transactions, litigations, trials, etc.), ii) No. of forward citations, iii) related to claims, and iv) related to references. Claims-related aggregate data includes i) number of open/registered claims and increase rate, ii) number of independent claims, and iv) average length/composition of independent claims in open/registered and increase rate. Aggregate data related to references include i) Total No. of references, ii) No. of patents among references, etc.
Keyword data by patent
Per patent, keywords are identified and extracted by specific fields such as title of invention, abstract, and patent claims. Extracted keywords may optionally contain classification information. See [Link] for more information on keyword classification.
Events data by patent
Events include i) transactions (assignments), ii) litigations, iii) judgments, iv) government-funded R&D achievements, v) standards, v) FDA approvals, etc. Each event has an event bibliography, including i) event parties (assignor/assignee, plaintiff/defendant, etc.), ii) date, iii) event identification data, and iv) event ancillary data (for litigations, court, judge, complaint, patents involved in the litigation, etc.).
For transactions, there are i) assignor, ii) assignee, and iii) transaction (assignment), which can be subdivided into: i) purchased/sold, ii) transfer through M&A, iii) setting and releasing of exclusive/non-exclusive practice rights (license), iv) setting and releasing of security, etc.
Related patents data per patent
Related patents include i) cited patents, ii) forward citations, iii) family patents, and iv) highly similar patents. Subdivisions of cited-cited patents include i) cited-cited by examiners, ii) self-forward citations by examiners in office actions, and iii) OA cited-cited.
Company name or company identification number data → Nearly anything that can be generated by a company
Company/organization identification within the patent world vs. outside the patent world
For Korean companies or organizations, we identify companies with the official mapping data between "application number (assigned by the Intellectual Property Office) vs. corporate registration number/business number (assigned by the nation)" provided by the Korean Intellectual Property Office (KIPO). Because of this, the accuracy of the mapping is very high at the upper level, even with other numbers outside the patent world (e.g., listed company codes) that are matched 1:1 with the corporate registration number.
However, for overseas companies (e.g., Apple) that applied to the Korean Intellectual Property Office, there is no mapping of 'application number (given by the intellectual property office) vs. corporate registration number (given by the nation)', so we only use the applicant code. As a result, the accuracy of mapping to data outside the patent world is limited.
However, within a nation, the applicant code, which is assigned at the level of the nation's intellectual property office, can be used with high reliability for mapping between 'Applicant Name vs. Applicant Code vs. Patent'. In other words, in countries such as Korea and Japan, which operate an applicant code system, the applicant code can be used to map patent sets. However, in the United States of America, China, Europe, etc., applicant codes are not open, so patent sets must be mapped by applicant name, and the accuracy will be relatively lower than in Korea and Japan.
Patentset data by company
We generate company-specific patent data with patent sets for each nation corresponding to each company. Since each patent has i) bibliographic data by patent, ii) keyword data by patent, iii) events data by patent, and iv) related patents by patent, we can combine these i) ~ iv) data into company-specific patent sets.
The combined data can also be aggregated in several ways. Representative aggregated data include i) time series, ii) time series by keywords, iii) time series by events, iv) time series by right holders of related patents, vi) time series by patent classification or other classifications, vi) time series by inventors, and any combination of these.
In other words, a company-specific patentset can extract (almost) all the information contained in a company's individual patents; thus, the extracted (almost) all information can be processed into company-specific data.
Patent classification data → Nearly everything that can be generated by patent number
Formality of patent set by patent classification
Patent classifications include i) IPC/CPC, which are global standard patent classifications, and ii) USPC, FI, F-term, which are individual nation standard patent classifications. IPC has about 70,000 patents, and every nation's patents are assigned IPC. There are about 260,000 CPCs, and most nations assign a CPC to each patent. Most advanced technologies also have an official CPC, making it the most versatile of the patent classifications. FIs, with a composition of over 140,000, and F-terms, with nearly 400,000, are common only in Japan.
Each nation's intellectual property office examiners assign at least one official patent classification to each patent, making patent sets by patent classification the most reliable official patent sets.
Patent Set Data by Patent Classification
This is a patentset for each nation corresponding to each patent classification, which generates patent data by patent classification. Since each patent has i) bibliographic data by patent, ii) keyword data by patent, iii) events data by patent, and iv) related patents data by patent, these i) ~ iv) data can be combined into a patentset by patent classification.
A patentset by patent classification extracts (almost) all the information contained in individual patents mapped to a patent classification, and can be processed to.
User patent data with/without mapped own classification → Nearly everything that can be generated from a patent number
Processing of patent sets by own classification in possession
The patents in possession may contain their own classifications (e.g., technology classification trees, etc.). In this case, you can generate processing data by patent while retaining the self-classification.
A patentset by self-classification extracts (almost) all the information contained in individual patents, which can then be aggregated and processed by self-classification.
If a user maps a patentset by hand for a specific keyword expression, this data falls into this category.
Keyword data → Nearly everything that can be generated by a patent number
The uniqueness of patentsets by keyword
Keywords have a slightly different attribute than companies, patent classifications, etc. Given a specific keyword (e.g., augmented reality), it is common for people to have different criteria for the patentsets that map to this keyword. Given a keyword, different people may differ in i) the conceptual/content scope that the keyword refers to (e.g., augmented reality itself, parts/ingredients/element technologies/implementation methods for augmented reality, etc...there are a myriad of related upper/lower/equivalent concepts/content, etc.), ii) the agreed/similar/associated expressions (e.g., is mixed reality included or separate), and iii) the extraction location (e.g., title of invention, abstract, claims, description of invention, drawings, etc..... ) may also differ.
For these reasons, it is by no means easy/simple to map patentsets by keyword in a day to day basis; hence, it is advisable to utilize patentset data by keyword (with a certain amount of tolerance), while recognizing its obvious limitations. As long as the limitations are clearly recognized, processed patent data by keyword can be a high-value data with multiple applications, especially since keywords are virtually the only common access point to non-patent data such as papers, SW, news, social, etc.
For PatentPia keyword data, please refer to i) Keyword identification, ii) Keyword classification, iii) Co-occurring keywords, iv) Recommended keywords with high possibility of technology convergence, v) Technology sensing, vi) Keyword analysis contents, etc.
Other special conditions → Nearly everything data that can be generated by patent numbers
Examples of special conditions
In addition to common conditions such as company, patent classification, keyword, etc. there can be patent sets by various conditions.
Just to name a few examples: i) US national R&D achievement patents (e.g., R&D achievement patents funded by Darpa, part of the US Department of Defense), ii) patents that NPE possessed or has unusual behavior, iii) listed companies by nation, theme(e.g., AI startup companies) / group(e.g., Samsung group affiliated companies, etc.)/companies by investment-financial events (e.g., companies that Google has made M&A with, etc.), iv) patents by right holders from (a particular nationality)/region (address, e.g., tax haven), v) patents by inventors from (a particular country/region (address)/ethnicity), vi) standard-essential patents, or patents related to FDA approvals.
Processing patent sets with special conditions
After extracting the patentsets corresponding to the special conditions, we generate the special condition-specific processed patent data by following the same steps.