
데이터 필요 시 활용 지도
PatentPia 데이터 자산 지도
PatentPia가 보유하고 있는 대표적인 데이터 자산에는 i) 특허/비특허 데이터 자산, ii) 키워드/기업 등에 대한 분류 자산이 있습니다.
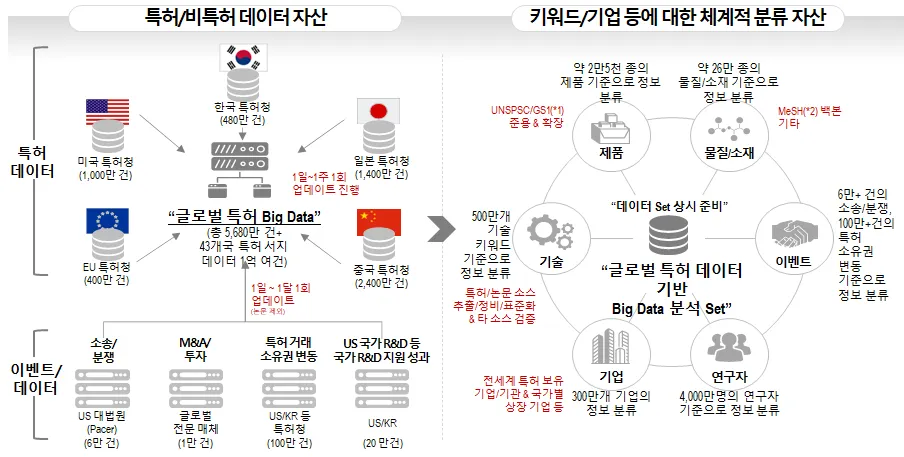
PatentPia 데이터 자산 로드맵
PatentPia는 글로벌 특허 데이터를 기반으로 한 데이터 자산을 보유하고 있습니다. 현재, 논문 및 웹 데이터 자산을 구축하고 있으며, 최종적으로는 국가별 산업-기술 정책 데이터를 기존 데이터 자산과 결합합니다.
특허 데이터 가공 소개
특허 번호 데이터(with/without 분류) → 특허 번호로 생성 가능한 nearly everything 데이터
특허 번호에 분류가 맵핑되어 있을 경우, 최종 데이터에서도 분류 맵핑 정보가 결합되어 제공됩니다.
특허별 데이터는 특허 1개당 1개가 대응되는 데이터와 n개가 대응되는 데이터가 있습니다. 특허별로 1개가 대응되는 데이터로 i) 날짜, ii) 번호, iii) 여부, (연도별)총계/측정값 등이 있습니다. 특허별로 n개가 대응되는 데이터로, i) 권리자, ii)발명자, iii) 특허 분류, iv) 각 국가별 연관 특허, v) 연관 이벤트, vi) 키워드, vii) 대리인 등이 있습니다.
특허별 1:1 대응 서지 및 집계 데이터
특허별 서지 데이터에는 1:1 대응 데이터 뿐만 아니라, 1:n 대응되는 i) 권리자, 발명자, 대리인 등의 주체 데이터, ii) 특허 패밀리가 있는 국가 데이터 등도 포함되어 있습니다.
권리자의 경우 권리자의 기관 속성으로 i) 기업 여부, ii) 대학/연구 기관 여부, iii) NPE 여부 등이 있습니다. 권리자의 국적, 특허권자의 소재지가 tax haven 여부 등과 같은 권리자 부가 데이터도 포함되어 있습니다. 한편, 거래된 특허인 경우, 권리자도 i) 현재 권리자, ii) 직전 권리자, iii) 출원인 등으로 세분화되어 제공됩니다.
그리고, 집계 데이터로, 연도별 및 전체 i) 이벤트 데이터(거래, 소송, 심판 등), ii) 피인용수, iii) 청구항 관련, iv) 레퍼런스 관련 집계 데이터가 있습니다. 청구항 관련 집계 데이터에는 i) 공개/등록 청구항수 및 증감율, ii) 독립 청구항 수, iv) 공개/등록 시 독립 청구항의 평균적 길이/구성 요소수 및 증감율 등이 있습니다. 레퍼런스 관련 집계 데이터에는 i) 레퍼런스 총 개수, ii) 레퍼런스 중 특허수 등이 있습니다.
특허별 키워드 데이터
특허별로, 발명의 명칭, 초록, 특허 청구 범위 등 특정 필드별로 키워드를 식별 및 추출합니다. 추출된 키워드에는 선택적으로 분류 정보가 포함되어 있을 수 있습니다. 키워드 분류에 대한 상세한 사항은 [Link]를 참조하세요.
특허별 이벤트 데이터
이벤트에는 i) 거래(양도), ii) 소송, iii) 심판, iv) 국가 R&D 성과, v) 표준, v) FDA 승인 등이 있습니다. 각종 이벤트에는 i) 이벤트 관계자(양도인/양수인, 원고/피고 등), ii) 날짜, iii) 이벤트 식별 데이터, iv) 이벤트 부가 데이터(소송의 경우에 법원, 판사, 소장, 소송에 함께 사용된 특허 등) 등과 같은 이벤트 서지가 있습니다.
거래의 경우에는 i) 양도인, ii) 양수인, iii) 거래(양도)를 세분화하면, i) 매입/매각, ii) M&A를 통한 이전, iii) 전용/통상 실시권(라이센스) 설정과 해제, iv) 담보 설정과 해제 등이 있습니다.
특허별 연관 특허 데이터
연관 특허에는 i) 인용 특허, ii) 피인용 특허, iii) 패밀리 특허, iv) 유사성 높은 특허 등이 있습니다. 인용-피인용 특허를 세분화하면, i) 심사관 인용-피인용 여부, ii) 자기(self) 인용-피인용 여부, iii) OA 인용-피인용 여부 등이 있습니다.
기업명 또는 기업 식별 번호 데이터 → 기업별로 생성 가능한 nearly everything 데이터
특허 세계 내 vs. 특허 세계 밖에서의 기업/조직 식별
대한민국 기업 또는 조직의 경우에는 대한민국 특허청(KIPO)가 제공하는 ‘출원인 번호(특허청 부여) vs. 법인 등록 번호/사업자 번호(국가 부여)’간의 공식적 맵핑 데이터로 기업을 식별합니다. 이 때문에 맵핑의 정확도는 최상위 수준으로 높습니다. 이에 따라, 법인 등록 번호와 1:1로 매칭되는 특허 세계 밖의 다른 번호(예, 상장법인 코드)와도 맵핑 정확도는 아주 높을 수 밖에 없습니다.
하지만, 대한민국 특허청에 출원한 해외 기업(예, 애플) 등은, ‘출원인 번호(특허청 부여) vs. 법인 등록 번호(국가 부여)’ 맵핑이 없기 때문에, 출원인 코드만을 사용합니다. 이에 따라, 특허 세계 밖의 데이터와의 맵핑 정확도에는 한계가 있을 수밖에 없습니다.
다만, 국가의 특허청 단위로 부여되는 그 국가 내에서의 출원인 코드는 그 국가 내에서, ‘출원인 명칭 vs. 출원인 코드 vs. 특허’ 간의 맵핑에는 높은 신뢰도로 사용될 수 있습니다. 즉, 출원인 코드 체계를 운영하는 대한민국, 일본 등에서는 출원인 코드를 활용하여, 특허셋을 맵핑할 수 있습니다. 하지만, 미국, 중국, 유럽 등에서는 출원인 코드를 공개하지 않고 있어, 출원인 명칭으로 특허셋을 맵핑해야 하기 때문에, 정확도는 한국이나 일본보다 상대적으로 낮게 됩니다.
기업별 특허셋 데이터
기업별로 대응된 각 국가별 특허셋으로, 기업별 특허 데이터를 생성합니다. 각 특허 마다에는 i) 특허별 서지 데이터, ii) 특허별 키워드 데이터, iii) 특허별 이벤트 데이터, iv) 특허별 연관 특허 데이터가 있으므로, 이러한 i) ~iv) 데이터를 기업별 특허셋으로 합칠 수 있습니다.
그리고, 합친 데이터는 여러 측면에서 집계할 수도 있습니다. 대표적인 집계 데이터에는 i) 시계열, ii) 키워드별 시계열, iii) 이벤트별 시계열, iv) 연관 특허의 권리자별 시계열, vi)특허 분류 또는 기타 분류별 시계열, vi) 발명자별 시계열 및 이들이 복합된 시계열 데이터 등이 있습니다.
즉, 기업별 특허셋은 기업의 개별 특허에 포함된 (거의) 모든 정보를 추출할 수 있습니다. 따라서, 추출된 (거의) 모든 정보를 기업별 데이터를 가공할 수 있습니다.
특허 분류 데이터 → 특허 번호로 생성 가능한 nearly everything 데이터
특허 분류별 특허셋의 공식성
특허 분류에는 i) 글로벌 표준 특허 분류인 IPC/CPC, ii) 개별 국가 표준 특허 분류인 USPC, FI, F-term 등이 있습니다. IPC는 약 7만개로 되어 있으며, 모든 국가의 특허에는 IPC가 부여되어 있습니다. CPC는 약 26만개로 되어 있으며, 대부분의 국가에서 특허마다 CPC를 부여하고 있습니다. 대다수의 첨단 기술에도 공식적인 CPC가 부여 되어 있으므로, 특허 분류 중에서는 CPC의 활용성이 가장 높습니다. 14만여개로 구성되는 FI 및 40만 여개에 가까운 F-term은 일본에서만 통용됩니다.
각 국가 특허청 심사관은 특허별로 적어도 1개 이상의 공식적인 특허 분류를 부여합니다. 따라서, 특허 분류별 특허셋은 가장 신뢰할 수 있는 공식적인 특허셋이 됩니다.
특허 분류별 특허셋 데이터
특허 분류별로 대응된 각 국가별 특허셋으로, 특허 분류별 특허 데이터를 생성합니다. 각 특허 마다에는 i) 특허별 서지 데이터, ii) 특허별 키워드 데이터, iii) 특허별 이벤트 데이터, iv) 특허별 연관 특허 데이터가 있으므로, 이러한 i) ~iv) 데이터를 특허 분류별 특허셋으로 합칠 수 있습니다.
특허 분류별 특허셋은 특허 분류에 맵핑된 개별 특허에 포함된 (거의) 모든 정보를 추출하여, 가공할 수 있습니다.
사용자 특허 데이터 with/without 맵핑된 자체 분류 → 특허 번호로 생성 가능한 nearly everything 데이터
보유 자체 분류별 특허셋의 가공
보유하고 있는 특허셋에 자체 분류(예, 테크 트리 등)가 포함되어 있을 수 있습니다. 이 경우, 자체 분류를 유지한 채, 특허별로 가공 데이터를 생성할 수 있습니다.
자체 분류별 특허셋은 개별 특허에 포함된 (거의) 모든 정보를 추출하여, 자체 분류별로 집계 및 가공할 수 있습니다.
특정 키워드 표현에 대해서 사용자가 직접 특허셋을 맵핑한다면, 이 데이터는 본 범주에 속합니다.
키워드 데이터 → 특허 번호로 생성 가능한 nearly everything 데이터
키워드별 특허셋의 특별성
키워드 기업, 특허 분류 등과는 조금 다른 속성을 가집니다. 특정 키워드(예, augmented reality)가 있을 때, 이 키워드에 맵핑되는 특허셋에 대한 기준은 사람마다 다른 것이 일반적입니다. 키워드가 주어졌을 때, 사람마다 그 키워드가 i) 지칭하는 개념적/내용적 범위(augmented reality 자체, augmented reality를 위한 부품/소재/요소 기술/구현 방법 등…무수하게 많은 연관 상위-하위-대등 개념/내용 등이 있음), ii) 동의/유사/연관 표현(예, mixed reality가 포함되느냐 별개냐)가 다를 수 있으며, iii) 추출 위치(예, 발명의 명칭, 초록, 특허청구범위, 발명의 설명, 도면 등….)도 다를 수 있습니다.
이와 같은 이유로, 키워드별 특허셋을 일의적으로 맵핑하는 것은 결코 쉬운/단순한 일이 아닙니다. 따라서, 키워드별 특허셋 데이터는 분명한 한계점을 인식한 상태에서, (일정 수준의 관용을 더하여) 활용하는 것이 바람직합니다. 한계점만 명확히 인식한다면, 키워드별 가공 특허데이터는 다양한 활용도를 가지는 고부가가치 데이터가 됩니다. 특히, 논문, SW, 뉴스, 소셜 등과 같은 비특허 데이터에 access할 수 있는 사실상 유일한 공통 접근 통로는 키워드 밖에 없는 것이 현실이기도 합니다.
PatentPia 키워드 데이터에 대해서는 i) 키워드 식별, ii) 키워드 분류, iii) 동시 출현 키워드, iv) 연결 가능성(융합) 높은 키워드 추천, v) 테크 센싱, vi) 키워드 분석 콘텐츠 등을 참조해 보세요.
기타 특별한 조건 → 특허 번호로 생성 가능한 nearly everything 데이터
특별한 조건의 예시
기업, 특허 분류, 키워드 등과 같은 일반적인 조건 이외에도 다양한 조건별 특허셋이 있을 수 있습니다.
대표적인 예시를 몇개만 든다면, i) US 국가 R&D 성과 특허(예, US 국방부 산하 Darpa가 펀딩한 R&D 성과 특허 등), ii) NPE 보유 또는 특이 행위 특허, iii) 국가별 상장사, 테마(예, AI startup 기업 등)/집단(예, 삼성 그룹 계열사 등)/투자-재무 이벤트(예, Google이 M&A한 기업 등)별 기업, iv) (특정 국적(nationality)/지역(address, 예, tax haven 소재)의 권리자의 특허, v) 특정 국가/지역(address)/인종(ethinicity)의 발명자의 특허, vi) 표준 특허나 FDA 승인에 사용된 특허 등이 있습니다.
특별한 조건별 특허셋의 가공
특별한 조건에 대응되는 특허셋을 추출한 다음, 동등한 후속 과정을 거쳐 특별한 조건별 가공 특허 데이터를 생성합니다.