

사람 데이터 지도
데이터 출처
PatentPia 사람(발명자, 논문 저자, SW 개발자 등) 데이터의 주요 출처에는 i) 전세계 1억건 이상의 특허 데이터, ii) 2억5천만건 이상의 논문 데이터 및 iii) 천만 건 이상의 GitHub SW(repository)에 대한 개발자 데이터 등이 있습니다.
사람 관련 문서셋의 특정
사람 관련된 문서셋은 i) 특허 발명자인 경우, 그 사람이 발명한 특허 문서셋, ii) 논문 저자인 경우 저술에 참여한 논문(제1저자 참여한 논문은 coming soon), iii) SW 개발자인 경우 그 사람이 참여한 SW(repository)셋으로 특정 됩니다.
사람 데이터 활용 체계
사람 데이터에 대한 활용 체계는 다음과 같이 요약할 수 있습니다. 아래는 특허 발명자(연구자)를 중심으로 하는 체계이나, 논문 저자 또는 SW 개발자에 대해서도 적용될 수 있습니다.
사람 관련 분석 콘텐츠 체계
사람 데이터 활용 체계를 지원하기 위해서, 개별적인 사람에 대해서 다음과 같은 분석 콘텐츠가 제공될 수 있습니다.
발명자(연구자) 1인별로 위의 그림과 같은 데이터 체계가 갖춰지면, 특정된 범주 별로 발명자(연구자)에 대한 비교 분석이 가능합니다. 대표적인 범주에는 i) 분야, ii) 기업/조직, iii) 기업/조직의 분야가 있습니다. 분야에는 i) 키워드, ii) CPC 등의 특허 분류, iii) 기술 카테고리 등과 같은 것들이 있습니다. 이들 분야는 속성별로, 기술, 제품-부품, 소재-물질, 질병 등 다양한 것들이 있을 수 있습니다.
논문 저자의 경우, 논문 저술, 피인용, 점유율과 집중률, 그리고 키워드 및 관련 연구자 부분은 특허 발명자와 동등합니다. 다만, 논문에서는 거래/소송 등과 같은 각종 이벤트가 없으며, 특허 패밀리 등과 같은 특허 고유의 데이터도 없습니다.
SW 개발자의 경우, 피인용에 대응될 수 있는 스타나 포크 등과 같은 독특한 체계가 있습니다. 한편, 키워드와 관련 개발자는 SW 개발자에 대해서도 동등하게 적용됩니다.
아래는 사람 관련 분석 콘텐츠에 대한 예시입니다.
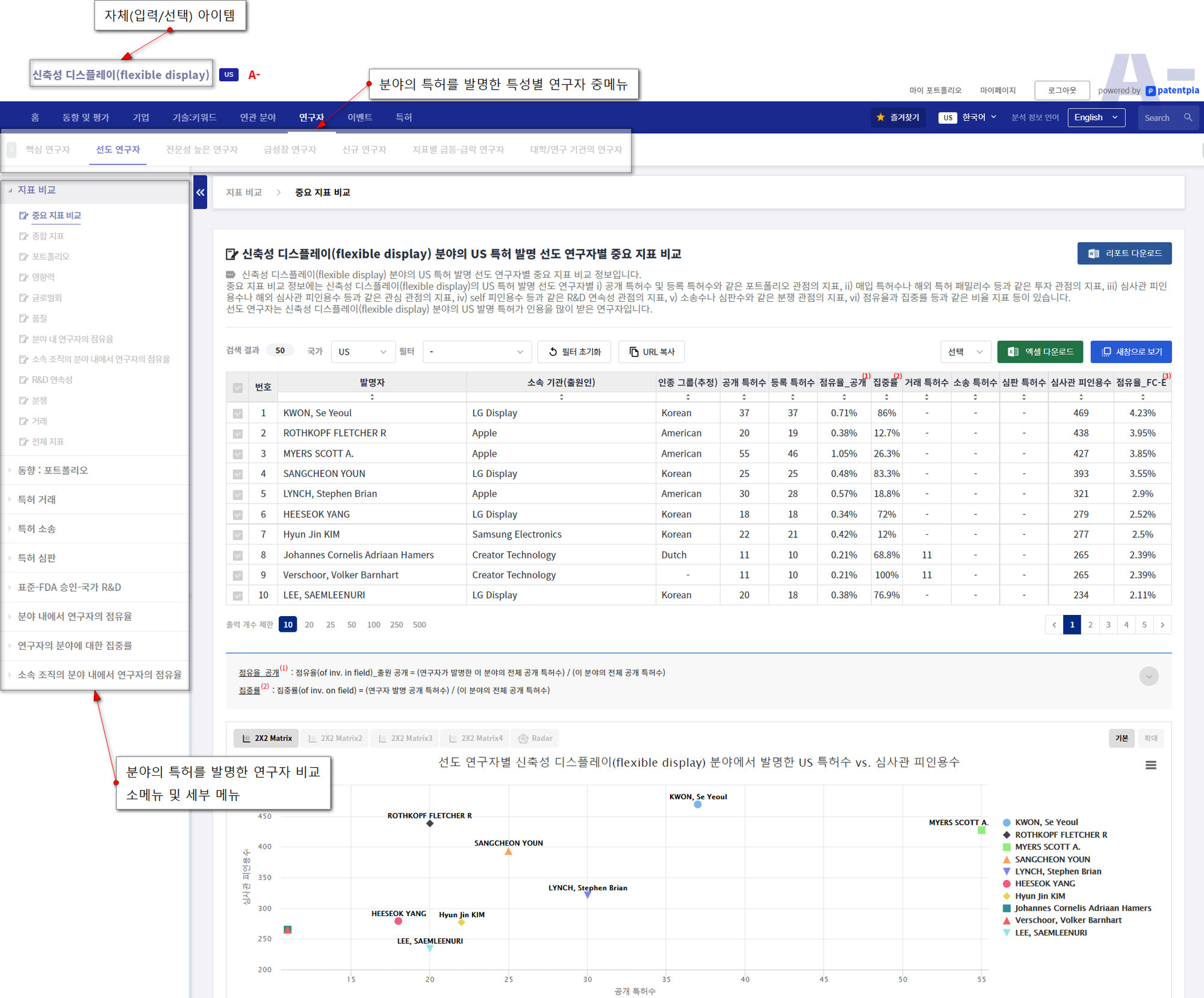
예시적으로, 플렉스블 디스플레이(flexible display) 분야의 특허 발명 핵심 연구자에 대한 예시입니다.
특정 기술 분야에 대한 발명자별로 비교할 수 있는 비교 분석의 종류에는 i) 지표 비교, ii) 동향 비교, iii) 피인용 비교, iv) 특허 패밀리 비교, v) 품질 비교, vi) 이벤트 종류별 비교, vii) 점유율 비교 및 viii) 집중률 비교가 있습니다.
사람 콘텐츠 관련 참조 링크
발명자 콘텐츠 관련하여 다음 링크를 참조하시면 좋습니다.
사람 데이터 처리 프로세스
다음은 사람 데이터 처리 프로세스입니다.
사람 식별의 어려움
국가는 사람에 대한 식별자(예, 주민등록번호 등)를 부여하여 운영하고 있지만, 이러한 식별자는 개인 정보로 공개되지 않습니다. 이에 따라, 데이터에서 표현되는 사람의 이름만으로, 사람의 고유성을 식별하는 것은 거의 불가능에 가깝습니다.
사람 식별에는 i) 동명 이인(이름 표기는 같은데, 실제로는 다른 사람), ii) 2개 언어에서는 이름 표기의 상이성(특히, middle name) 등과 같은 어려운 난제가 있습니다.
PatentPia에서의 사람 식별
특허 데이터 내 발명자 식별
PatentPia에서는 발명자 식별 단위는 ‘출원인 & 발명자 표기’입니다. 동일 출원 내에서는 동명 이인은 없다고 가정하고, 이름 표기가 같더라도 출원인이 다르면 다른 발명자라고 가정합니다. 주소 등을 통해서 보정하는 방법도 고려될 수 있지만, 이사(주소 이전) 등의 부수되는 문제로 주소 데이터를 사용하는 사람 식별/구별도 득보다는 실이 많습니다. LinkedIn 등에 있는 Experience(소속 조직 이동 경력)을 통해서 보충할 수도 있지만, 이 또한 여러가지 문제점을 가지고 있습니다.
특허 vs. 논문 간 사람 동일성 맵핑
PatentPia는 특허 데이터에서 표기되는 발명자와 논문 저자 간의 매칭을 연구하고 있습니다.